Raft基础理论
1 分布式日志系统
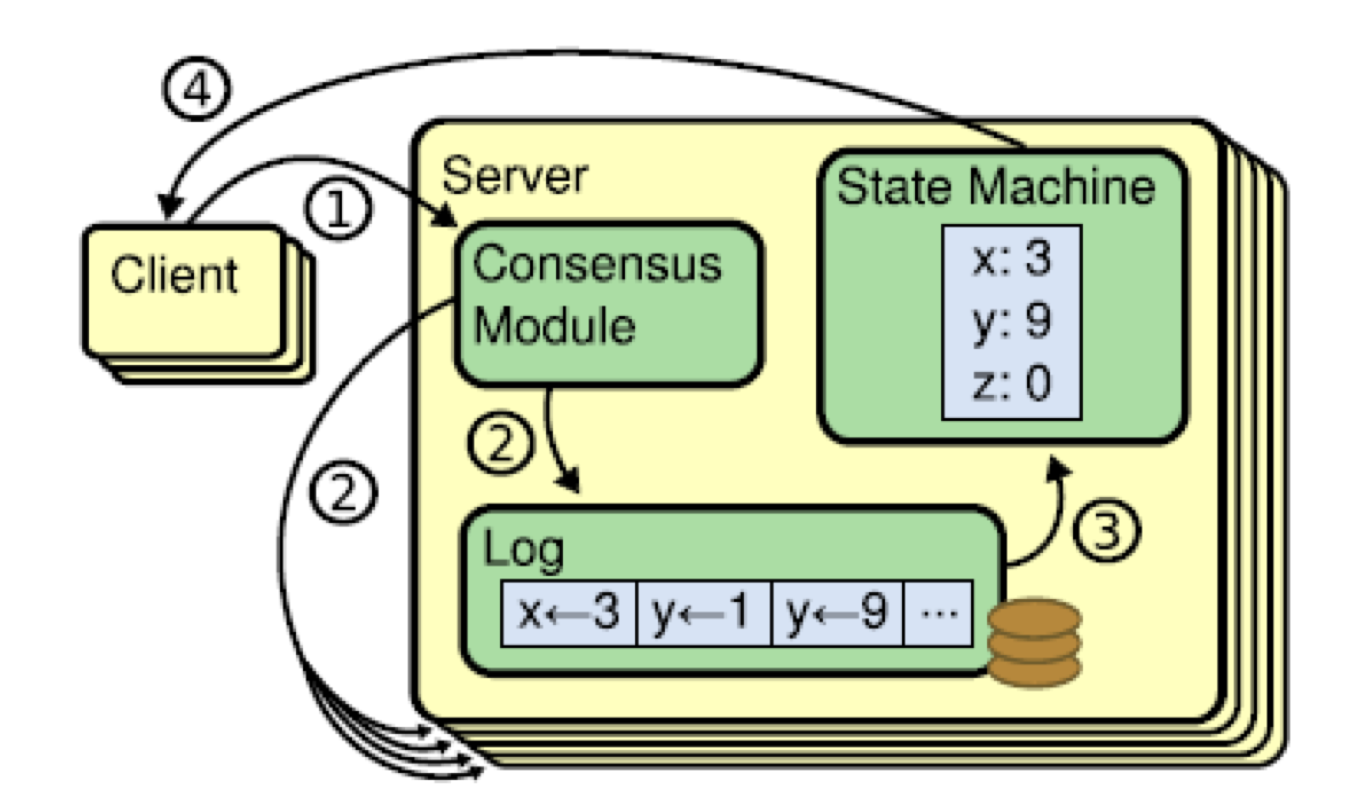
分布式日志系统包括三个部分:
- 共识算法: 负责确定
Client commands的顺序 - 日志:记录经过共识的有序的
Client commands - 状态机: 负责执行
client commands
2. Raft共识算法一致性准则
- Election Safety: 指定任期,仅可以有1个leader
- Leader Append Only: Leader不会重写或删除日志,仅会添加新的entries
- Log Matching: 一致性,即:若两个logs的指定entry包含相同的
log index和term,则到指定entry之前的所有entries都是一致的 - Leader Completeness: Leader必然包含最全的一致性数据,定义:若某个log entry在指定term被标记为
committed状态,则该entry会存在与所有拥有更高term的Leader的logs中 - State Machine Safety: 一致性,若指定节点的某个entry被标记为
committed状态,并被放到state machine中执行,则在相同的log index处,其他节点不会存在不同的log entry
3. Raft基本概念
3.1 日志(Log Entries)
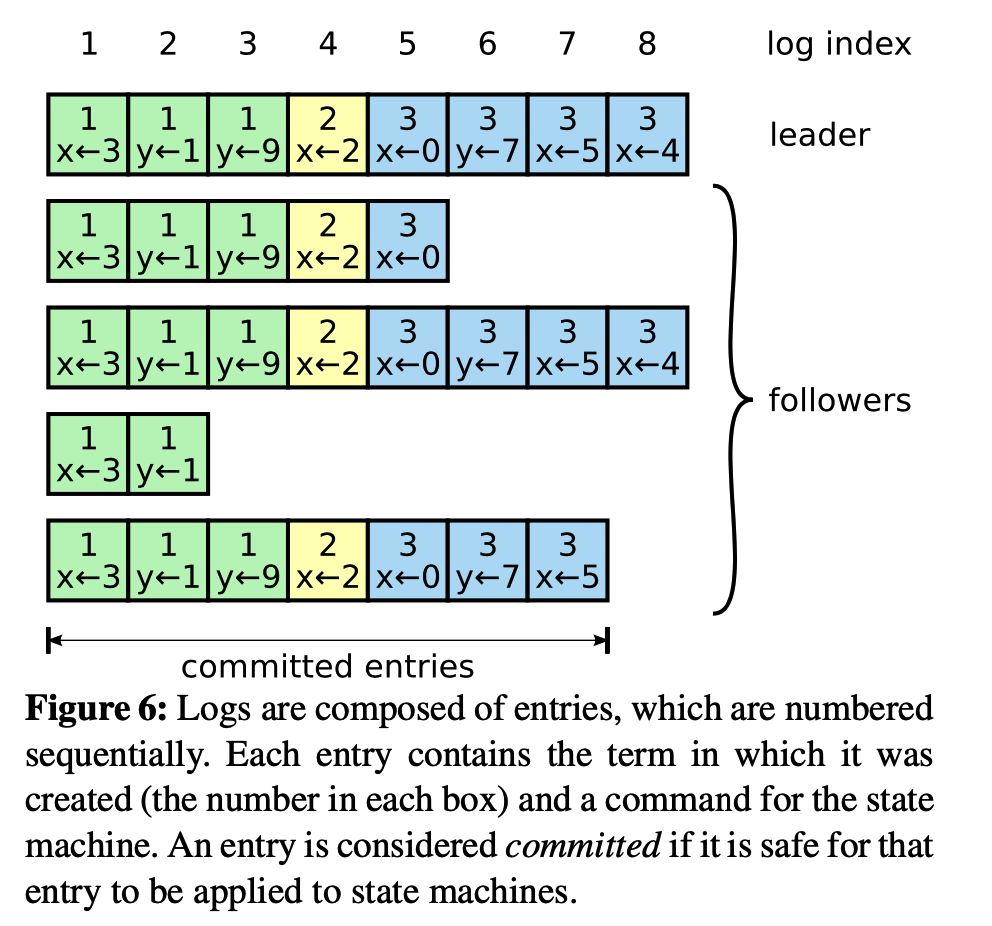
上图是Raft中的基本日志结构,主要包括:
term: 日志创建时的termcommand: 每条日志对应的命令log index: 日志索引
当日志由leader复制到超过一半的节点时,其被认为是committed状态:
某log entries N > commitIndex,且超过一半节点满足如下条件,可将该日志标记为commit状态,并将commitIndex设置为N`:
- 最新日志索引 >= N
Log[N].term==currentTerm
3.2 核心角色
Followers
- 接收
Candidates和Leader的消息包 - 接收
AppendEntries请求 - 对
candidates进行投票,选举Leader
Candidates
- term自增,竞选Leader,竞选过程中会发送
RequestVotes RPC请求到所有server - 当收到超过一半节点的投票:当选为Leader
- 当收到其他Leader的
AppendEntries(可能带有心跳或日志信息)请求,重新退化为Follower - Leader选举超时,term自增,开始发起下一轮选举
- 发现有节点的term更高,退化为
Follower
Leaders
- 初始化
nextIndex为最新log index + 1 - 向所有节点发送
AppendEntries RPC请求,表明存活状态 - 接收客户端的请求,并将客户端的请求中的
commands添加到本地日志中 -
探测到
follows的nextIndex小于本地最新的log index时,向该节点主动发送AppendEntries RPC消息包:- follows更新日志成功:更新其
nextIndex - follows更新日志失败: 修改
nextIndex,Leader基于新的nextIndex向该follow发送AppendEntries RPC消息包
- follows更新日志成功:更新其
- 将日志标记为
commit状态
日志Commit限制: Leader仅可将当前Term的日志标记为commit状态
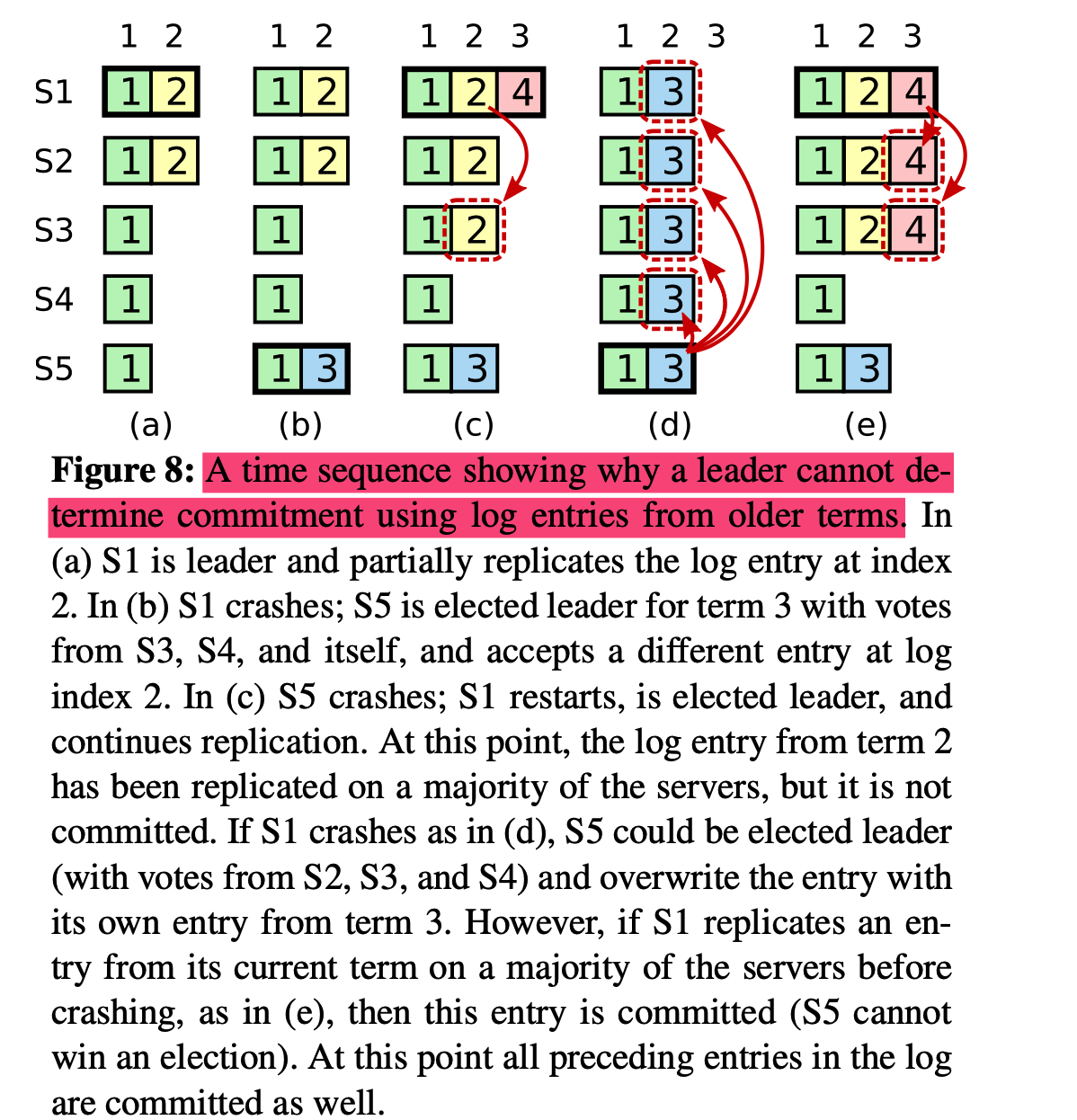
- a: s1在term2当选为Leader,产生日志(term2, log_index2),并将其复制到s2
- b: s1宕机,s5在term3当选为Leader,产生日志(term3, log_index2),并在还没开始复制日志到其他节点时就宕机
- c:s1恢复并在term4重新当选为Leader,产生日志(term4, log_index3),并尝试将(term2, log_index2)复制给s3
case1:
- d: s1刚将(term2, log_index2)复制s3,收到s3的回复就宕机了,但由于(term2 != term4),s1没有将(term2, log_index2)设置为commit状态;s5恢复后被当选为Leader,(term3, log_index2)的日志会覆盖(term2, log_index2)的日志;
case2:
- e:s1将(term4, log_index3)复制到大多数节点后宕机,此时(term2, log_index2) 和(term4, log_index3)都会被标记为
commit状态,由于s5的log_index小于s2和s3,不可能发生已经提交的日志被覆盖的情况
3.3 Raft日志冲突处理策略
Raft中可能出现的各种状态不一致的情况:

-
Follower节点与Leader节点日志冲突时,Leader节点会强制覆盖Follower节点上与Leader节点不一致的日志(注: 这种Strong Leader的策略不会有问题,因为
Follower节点与Leader节点不一致的日志一定是uncommit状态)
4. Raft核心处理流程
4.1 RequestVote(选举功能)
follower长时间没有接收到leader心跳,自动切换为candidate,触发leader选举流程:
candidate发送的选举消息包:
term:candidate当前的termcandidateId:candidatenodeIDlastLogIndex:candidate最新日志的indexlastLogTerm:candidate最新日志的term
其他节点收到该投票请求后的执行流程:
bool onReceiveVote(Message vote)
{
if(vote.term < currentTerm)
{
return false;
}
if((voteFor == null || voteFor == vote.candidateId) && (latestLogIndex <= vote.lastLogIndex && latestLogTerm <= vote.lastLogTerm))
{
voterFor = vote.candidateId;
return true;
}
}
执行结果:
- Term:当前投票节点的term
- voteGranted: 表明是否接收Candidiate的选票
4.2 AppendEntries(日志复制)
Leader将日志信息同步给其他replica:
Leader发送的消息包内容:
term: Leader的任期leaderId: Leader身份信息prevLogIndex: 已经被状态机执行的日志最大索引值, 即最新日志之前的日志的索引值.prevLogTerm: 已经被状态机执行的最新日志对应的termentries[]: 同步的日志信息leaderCommit: leader的commitIndex
结果:
term: 当前节点的termsuccess: 日志复制是否成功
执行过程:
bool appendEntries(Message leader)
{
// 1. 比较term,拒绝低于本地任期的消息包
if(leader.term < currentTerm)
return false;
// 2. 判断apply到状态机的最新日志状态是否一致
LogEntry::Ptr prevLog = findLog(leader.prevLogEntry);
if(prevLog != null && prevLog->term != leader.term)
{
return false;
}
// 3. 日志冲突处理
LogEntry::Ptr latestLog = getLatestLog();
if(latestLog->index == leader.entries[0].index && latestLog->term != leader.entries[0].term)
{
// 删除冲突的log entries
deleteConflictLog(latestLog);
}
// 4. 将最新的log entries复制到本地
// 5. 更新commitIndex
int64_t appendIndex = getMaxIndex(leader.entries[])
if(leader.leaderCommit > commitIndex)
{
commitIndex = min(leader.leaderCommit, appendIndex);
}
}
4.3 日志压缩
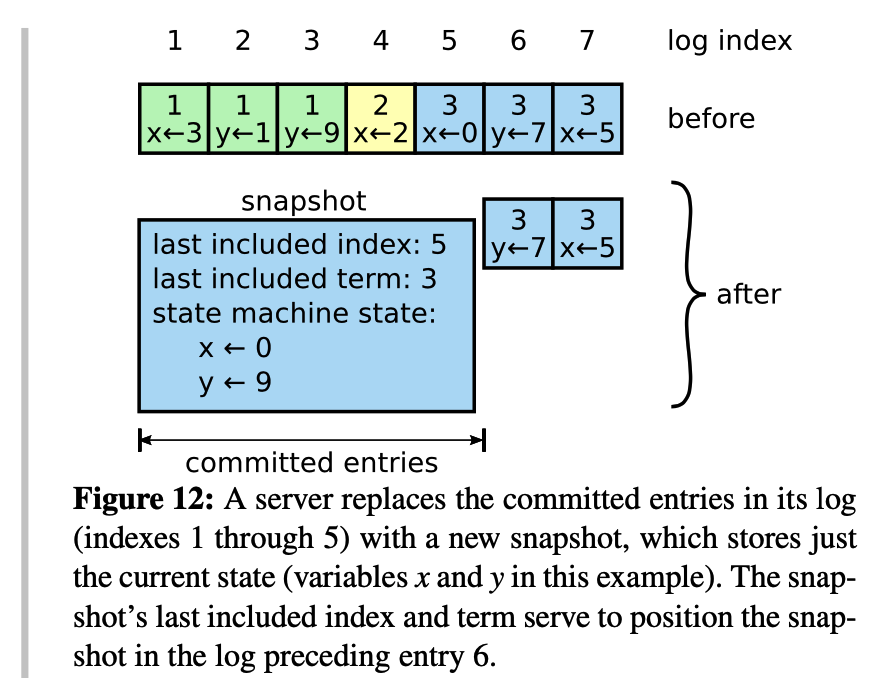
上图示例:用节点快照替换(term1, index1)到(term3, index5)日志序列
- 仅可压缩
commit状态的log entries - 日志压缩时,将
commit状态日志放到状态机中执行,输出最新状态 - 当某follower需要同步就日志,且日志已经被leader做了快照并删除,leader需将快照发送给follower
4.4 集群成员变更

本质: 将集群成员配置作为特殊的日志从leader节点同步到其他节点
上图展示了,直接切换集群配置会导致的脑裂问题:
-
该系统包括3个节点,server1~server3, server3为leader
-
server4, server5加入集群,新的集群配置从leader server3同步给其他节点
-
server3短暂宕机,触发server1和server5超时选主
-
由于server1仅存储旧配置,因此向server2, server3拉票;server2仅维护旧配置,投票给server1,由于Server1认为集群仅包含3个成员,因此当选为leader;
-
server5维护了最新配置,则向其他四个节点拉票,有新配置的server3, server4会给server5投票,server5认为集群有5个成员,当选为leader
——— 最终导致一个集群出现了两个leader,出现了脑裂
两阶段切换集群成员配置用来解决这个问题:(共同一致, joint Consensus)
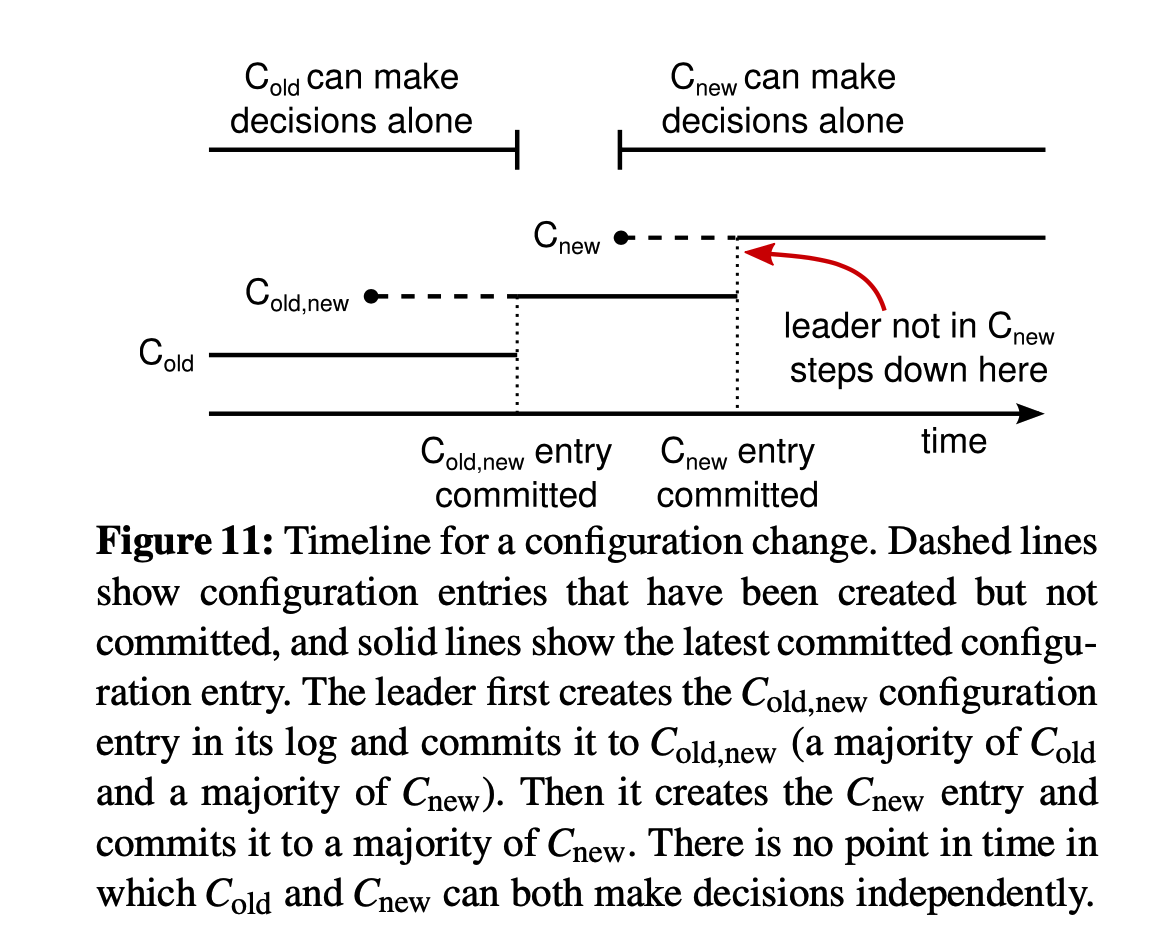
阶段一:
- 客户端将新配置C-new发送给leader,leader将C-old和C-new作为一个并集,并立即apply,记作C-old, new
- Leader将C-old, new包装为日志同步给其他节点
—- 【若此步Leader挂掉,则C-old, new只同步到了不超过一半节点,C-old占多数,重新选取Leader时,必须得到大部分C-old投票,Leader会从持有C-old日志的节点产生】
- Follwer收到C-old, new后立即apply,当C-old,new被大部分节点apply后,leader commit C-old, new日志
—— 【若此步Leader挂掉,则C-old, new已经同步到了大部分节点,新选出的Leader必然拥有C-old, new日志,不会出现两个Leader】
阶段二:
- Leader将C-new包装为日志同步给其他节点
- Follower收到C-new后立即apply,若此时发现自己不在C-new列表,则主动退出集群
—– 【若此步Leader挂掉,则C-new只同步到了不超过一半的节点,无论是C-old, new还是C-new节点发起选举,必须经过大部分C-new节点选举,因此不会出现两个Leader】
- Leader确认C-new的大部分节点都切换成功后,给客户端发送执行成功的响应
—— 【若此步Leader挂掉,则大部分节点都拥有C-new,可安全地从C-new中选取Leader】